Publications
ICCV 2025 [Oral]
LoftUp: Learning a Coordinate-Based Feature Upsampler for Vision Foundation Models
Vision foundation models (VFMs) such as DINOv2 and CLIP have achieved impressive results on various downstream tasks, but their limited feature resolution hampers performance in applications requiring pixel-level understanding. Feature upsampling offers a promising direction to address this challenge. In this work, we identify two critical factors for enhancing feature upsampling: the upsampler architecture and the training objective. For the upsampler architecture, we introduce a coordinate-based cross-attention transformer that integrates the high-resolution images with coordinates and low-resolution VFM features to generate sharp, high-quality features. For the training objective, we propose constructing high-resolution pseudo-groundtruth features by leveraging class-agnostic masks and self-distillation. Our approach effectively captures fine-grained details and adapts flexibly to various input and feature resolutions. Through experiments, we demonstrate that our approach significantly outperforms existing feature upsampling techniques across various downstream tasks.

ILR+G Workshop @ ICCV 2025 [Oral]
Benchmarking Feature Upsampling Methods for Vision Foundation Models using Interactive Segmentation
Vision Foundation Models (VFMs) are large-scale, pre-trained models that serve as general-purpose backbones for various computer vision tasks. As VFMs' popularity grows, there is an increasing interest in understanding their effectiveness for dense prediction tasks. However, VFMs typically produce low-resolution features, limiting their direct applicability in this context. One way to tackle this limitation is by employing a task-agnostic feature upsampling module that refines VFM features resolution. To assess the effectiveness of this approach, we investigate Interactive Segmentation (IS) as a novel benchmark for evaluating feature upsampling methods on VFMs. Due to its inherent multimodal input, consisting of an image and a set of user-defined clicks, as well as its dense mask output, IS creates a challenging environment that demands comprehensive visual scene understanding. Our benchmarking experiments show that selecting appropriate upsampling strategies significantly improves VFM features quality.

Journal of Molecular Structure 2025
The effect of protein structure on optical absorption spectra of oxyhemoglobin: the hybrid QM/MM study
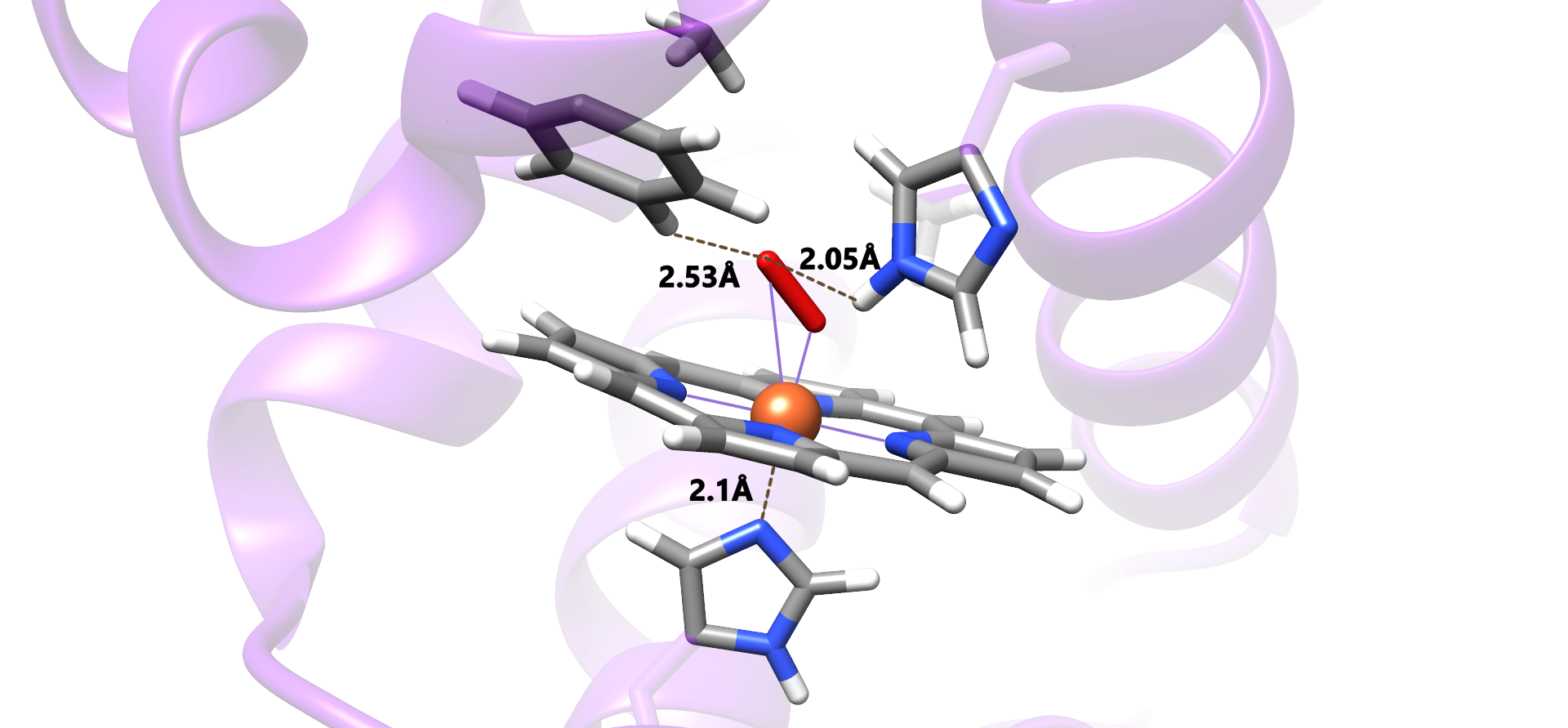
We present the results of a hybrid quantum mechanics/molecular mechanics (QM/MM) study examining the effect of protein structure on the geometrical and optical properties of oxyhemoglobin in its R (relaxed) state. The quantum mechanical region was modeled using density functional theory (DFT). Optimized structures and vibrational spectra were determined using the B3LYP/6–31G(d,p) approximation. Binding energies of the oxygen molecule to the Fe-porphyrin complex were calculated using various models. The values of the binding energies were obtained in the range of 24–38 kcal/mol.
The hydrogen bonds between oxygen and peripheral residues (distal histidine and phenylalanine) in the oxyhemoglobin were revealed. The oxyhemoglobin in α subunit is characterized by a stronger hydrogen bond between the oxygen and only distal histidine. In the β subunit, oxygen forms hydrogen bonds with both distant histidine and phenylalanine.
The structural differences between the α and β subunits of oxyhemoglobin significantly affect its optical properties, particularly in the optical absorption spectra. The protein environment induces a larger red shift in the Soret band of the β subunit compared to the α subunit. Solvation causes a significant redshift in the Soret band of the α and β subunits and in the Q-bands of the β subunit. Conversely, solvation induces a notable blue shift in the Q-bands for the α subunits.
NANO-2021
The effect of protein structure on O2 binding to heme: the hybrid QM/MM study
Poster presentation at NANO-2021. This research investigates the effect of protein structure on oxygen binding to heme using hybrid QM/MM simulations.